 The
LAVA
Lab
The
LAVA
Lab
Research on Branch Prediction
The
LAVA
Lab
Research on Branch Prediction
Improving branch prediction, although already a well-studied subject, remains critical because delivering very high branch-prediction rates is crucial to further performance gains in high-performance computing. For example, a single misprediction in the Alpha 21264 results in a minimum of 7 wasted cycles; in the Pentium 4, in a minimum of 17 wasted cycles. Because most processors today are out-of-order processors, branches can take an arbitrarily long time to resolve, and so the average misprediction penalty is often much larger, 10-20 cycles. It takes a "mere" 5% misprediction rate to cut performance by as much as 20-30% in today's wide-issue processors.
Our prior work has explored how to improve branch-prediction accuracy
by updating the predictor speculatively. Mis-speculated updates require
repair, and we have shown that some simple mechanisms can make this repair
possible at low cost. A particularly elegant example is speculative
update and repair of the return-address stack. It is sufficient
to simply save and restore the top-of-stack pointer and top-of-stack
contents. We have also shown that it makes sense to combine local and global
history in the same 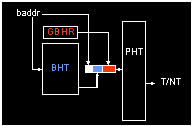 branch
predictor structurea pseudo-hybrid branch predictor that we call an alloyed
predictor. Using both global and local history is important.
Not only do some branches in a program benefit from global history while
others benefit from local historya well known fact that suggests use of
a hybrid predictorbut in fact individual branches vary between benefiting
from global history and benefiting from local history. A large, dynamic-selection
(McFarling-style)
hybrid predictor can also give good performance. But a hybrid predictor
is only effective with a large hardware budget. An alloyed predictor
is equally effective for large budgets, but is more robust, giving good
performance even down to 1 Kbits. An alloyed predictor consistently
outperforms conventional 2-level organizations, and also outperforms hybrid
predictors for all but the largest hardware budgets. The key is that
the alloyed organization is combining global and local history.
In a
branch
predictor structurea pseudo-hybrid branch predictor that we call an alloyed
predictor. Using both global and local history is important.
Not only do some branches in a program benefit from global history while
others benefit from local historya well known fact that suggests use of
a hybrid predictorbut in fact individual branches vary between benefiting
from global history and benefiting from local history. A large, dynamic-selection
(McFarling-style)
hybrid predictor can also give good performance. But a hybrid predictor
is only effective with a large hardware budget. An alloyed predictor
is equally effective for large budgets, but is more robust, giving good
performance even down to 1 Kbits. An alloyed predictor consistently
outperforms conventional 2-level organizations, and also outperforms hybrid
predictors for all but the largest hardware budgets. The key is that
the alloyed organization is combining global and local history.
In a
related vein, we have explored the
impact of context switching on branch-prediction accuracy and found
the impact to be negligible except for very small context-switch intervals.
In the power domain, as mentioned above, we have also analyzed the power characteristics of branch predictors. We find that, for overall dynamic power savings, it is important to obtain the highest possible branch-prediction accuracy, even if this entails extra power dissipation in the fetch engine. But some techniques, like the use of a prediction probe detector (PPD), can save power without sacrificing prediction accuracy. For static or leakage power savings, one can apply decay techniques or use a novel four-transistor RAM cell design. The dynamic power work is joint with Dharmesh Parikh, Yan Zhang, Marco Barcella, and Mircea Stan; the leakage power work is joint with Zhigang Hu, Philo Juang, Margaret Martonosi, and Doug Clark from Princeton, and Stefanos Kaxiras from Agere.
![]() New
work is characterizing and proving the limits of predicatabilitywork
with Karthik Sankaranarayanan.
We are also looking for new benchmarks that exhibit interesting branch-prediction
behavior, especially programs with poor predictability and/or a large branch
footprint. Take the benchmark challenge!
New
work is characterizing and proving the limits of predicatabilitywork
with Karthik Sankaranarayanan.
We are also looking for new benchmarks that exhibit interesting branch-prediction
behavior, especially programs with poor predictability and/or a large branch
footprint. Take the benchmark challenge!
![]() Future
work for which we need new group members includes (1) other
ways to improve branch prediction by improving compiler-hardware
synergy: we want to understand how aggressive predication and hardware
branch-prediction interact, and how compile-time data-, control-, and dependence
analysis can convey useful information to the runtime hardware without
the need for tedious profiling and feedback; and (2) and a variety of projects
to better characterize branch predictor behavior and the sources of branch
mispredictions.
Future
work for which we need new group members includes (1) other
ways to improve branch prediction by improving compiler-hardware
synergy: we want to understand how aggressive predication and hardware
branch-prediction interact, and how compile-time data-, control-, and dependence
analysis can convey useful information to the runtime hardware without
the need for tedious profiling and feedback; and (2) and a variety of projects
to better characterize branch predictor behavior and the sources of branch
mispredictions.
|
Back to Skadron's home page Back to the LAVA home page Last updated: 7 Mar., 2003 |
 |
Department of Computer Science
School of Engineering and Applied
Science
University of Virginia, Charlottesville,
Virginia 22904
(434) 982-2200, FAX: (434) 982-2214
Email web page comments to webman@cs.virginia.edu
Email CS admission inquiries to inquiry@cs.virginia.edu
© Kevin Skadron, 2001,2002