 The
LAVA
Lab
The
LAVA
Lab
The Laboratory for Computer Architecture
at Virginia
Unfortunately, this page has gradually drifted out of date.
Please see the revised page for
the most up to date information.
( Research Overview
| People & Support | Publications
| Facilities & Software )
Kevin
Skadron
Assistant Professor of Computer Science
Research in the LAVA Lab
Microprocessors are at the heart of the information revolution, and continuing
advances in information technology depend heavily on continuing advances
in our ability to design fast, efficient, and low-power processor architectures
(overview,
PDF). Our ability to analyze and develop new
computer architectures depends, in turn, on our ability to conduct accurate
simulation and performance analysis (overview,
PDF). The LAVA Lab therefore seeks to develop more
efficient architectures, novel architectures that break past the bottlenecks
of today's architectures, and simulation techniques that can accurately
model all these issues. In particular, the LAVA Lab is currently
focusing on projects in the following areas:
We are urgently seeking graduate students,
Fulbright Scholars and other fellows, and postdocs who are interested
in these research areas! (Why
prospective grad students should come to U.Va.) We are also seeking
undergraduates
to help with these projects–either over the summer, during the year for
pay, or for senior theses.
A list of prior U.Va. research projects in computer architecture can
be found
here.
Low Power and
Thermal Management
In recent years power dissipation has become an area of intense concern
to the designers of microprocessors for a variety of reasons. Today's processors
stress current-delivery mechanisms and require sophisticated and expensive
thermal packages to control heat dissipation, and battery life is perennial
concern. Reducing power dissipation helps mitigate all these problems.
While circuit-level techniques have been a mainstay for years for managing
power dissipation, architecture-level techniques offer the promise of additional
and synergistic techniques for managing power because they can take advantage
of additional knowledge about the runtime behavior of the current workload.
Unfortunately, most architecture-level power and thermal management techniques
impede processing speed, because they operate by turning off or slowing
down part or all of the processor. The challenge therefore lies in
finding power-management techniques that minimize the consequent loss in
performance. This is joint work with Mircea
Stan from the U.Va. ECE department
and Tarek Abdelzaher from
the CS department and Margaret
Martonosi at Princeton University.
In the area of thermal management, we have developed a computationally
efficient, first-order model for localized heating on the microprocessor
die, and shown how control theory can be an effective tool for tight regulation
of on-chip temperatures. This
work appears in a paper in HPCA-8. A more accurate model and
a comparison of many dynamic-thermal-managemenet techniques appears in
a paper in ISCA-30. It is important to note that metrics based purely
on an average of power or energy measurements do not predict temperature
well, and that many low-power techniques do not help in regulating
temperature!
We have also analyzed the power characteristics of branch predictors,
in
another paper appearing in HPCA-8. We find that, for overall
dynamic
power
savings, it is important to obtain the highest possible branch-prediction
accuracy, even if this entails extra power dissipation in the fetch engine.
But some techniques, like the use of a prediction probe detector
(PPD), can save power without sacrificing prediction accuracy. For
static
or leakage power savings, one can apply decay
techniques or use a novel
four-transistor RAM cell design. The 4T RAM cell can also be
used to design an effective decay
cache. Our work on leakage has also led us to develop a
model of leakage energy that is practical and useful for architects.
A beta version
of the HotLeakage software is now available for download.
Finally, we have shown the value of formal feedback control in power
and thermal management, using it to control
the DVS setting for a multimedia workload; using it to set
the decay interval for cache decay; and as mentioned above, using it
for thermal
regulation.
 Future
work: This is a wide-open research area--new group members are
needed to develop a variety of new techniques for thermal and power management
and modeling.
Future
work: This is a wide-open research area--new group members are
needed to develop a variety of new techniques for thermal and power management
and modeling.
Applications of
Control Theory
As adaptive techniques in processor architecture
become prevalent, we argue that they should be designed using formal feedback-control
theory. Control theory provides a powerful framework that simplifies the
task of designing an adaptive system. It provides well-known control designs
that are easy to tune for performance and stability. Open-loop adaptation,
on the other hand, is vulnerable to unacceptable behaviors when presented
with workloads or conditions that were not anticipated at design time.
In contrast, feedback control responds to unanticipated behaviors and provides
robust operation in cases where open-loop designs fail. Since interest
in adaptivity only continues to grow, the need for feedback control techniques
and formal design techniques can only grow accordingly.
As mentioned earlier in this page, so far we have
demonstrated a number of applications of control theory, including controlling
the DVS setting for a multimedia workload; setting
the decay interval for cache decay; and thermal
regulation.
Future
work: This is a wide-open research area--new group members are
needed to explore new applications and techniques.
Branch Prediction
Improving branch prediction, although already a well-studied subject, remains
critical because delivering very high branch-prediction rates is crucial
to further performance gains in high-performance computing. For example,
a single misprediction in the Alpha 21264 results in a minimum of 7 wasted
cycles; in the Pentium 4, in a minimum of 17 wasted cycles. Because
most processors today are out-of-order processors, branches can take an
arbitrarily long time to resolve, and so the average misprediction penalty
is often much larger, 10-20 cycles. It takes a "mere" 5% misprediction
rate to cut performance by as much as 20-30% in today's wide-issue processors.
Our prior work has explored how to improve branch-prediction accuracy
by updating the predictor speculatively. Mis-speculated updates require
repair, and we have shown that some simple mechanisms can make this repair
possible at low cost. A particularly elegant example is speculative
update and repair of the return-address stack. It is sufficient
to simply save and restore the top-of-stack pointer and top-of-stack
contents. We have also shown that it makes sense to combine local and global
history in the same 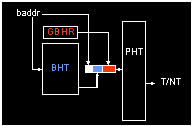 branch
predictor structure–a pseudo-hybrid branch predictor that we call an alloyed
predictor. Using both global and local history is important.
Not only do some branches in a program benefit from global history while
others benefit from local history–a well known fact that suggests use of
a hybrid predictor–but in fact individual branches vary between benefiting
from global history and benefiting from local history. A large, dynamic-selection
(McFarling-style)
hybrid predictor can also give good performance. But a hybrid predictor
is only effective with a large hardware budget. An alloyed predictor
is equally effective for large budgets, but is more robust, giving good
performance even down to 1 Kbits. An alloyed predictor consistently
outperforms conventional 2-level organizations, and also outperforms hybrid
predictors for all but the largest hardware budgets. The key is that
the alloyed organization is combining global and local history.
In a related vein, we have explored the
impact of context switching on branch-prediction accuracy and found
the impact to be negligible except for very small context-switch intervals.
branch
predictor structure–a pseudo-hybrid branch predictor that we call an alloyed
predictor. Using both global and local history is important.
Not only do some branches in a program benefit from global history while
others benefit from local history–a well known fact that suggests use of
a hybrid predictor–but in fact individual branches vary between benefiting
from global history and benefiting from local history. A large, dynamic-selection
(McFarling-style)
hybrid predictor can also give good performance. But a hybrid predictor
is only effective with a large hardware budget. An alloyed predictor
is equally effective for large budgets, but is more robust, giving good
performance even down to 1 Kbits. An alloyed predictor consistently
outperforms conventional 2-level organizations, and also outperforms hybrid
predictors for all but the largest hardware budgets. The key is that
the alloyed organization is combining global and local history.
In a related vein, we have explored the
impact of context switching on branch-prediction accuracy and found
the impact to be negligible except for very small context-switch intervals.
In the power domain, as mentioned above, we have also analyzed the power
characteristics of branch predictors. We find that, for overall
dynamic
power
savings, it is important to obtain the highest possible branch-prediction
accuracy, even if this entails extra power dissipation in the fetch engine.
But some techniques, like the use of a prediction probe detector
(PPD), can save power without sacrificing prediction accuracy. For
static
or leakage power savings, one can apply decay
techniques or use a novel
four-transistor RAM cell design. The dynamic power work is joint
with Dharmesh Parikh, Yan
Zhang, Marco Barcella, and Mircea
Stan; the leakage power work is joint with Zhigang Hu, Philo Juang,
Margaret
Martonosi, and Doug Clark
from Princeton, and Stefanos Kaxiras
from Agere.
New
work is characterizing and proving the limits of predicatability–work
with Karthik Sankaranarayanan.
We are also looking for new benchmarks that exhibit interesting branch-prediction
behavior, especially programs with poor predictability and/or a large branch
footprint. Take the benchmark challenge!
Future
work for which we need new group members includes (1) other
ways to improve branch prediction by improving compiler-hardware
synergy: we want to understand how aggressive predication and hardware
branch-prediction interact, and how compile-time data-, control-, and dependence
analysis can convey useful information to the runtime hardware without
the need for tedious profiling and feedback; and (2) and a variety of projects
to better characterize branch predictor behavior and the sources of branch
mispredictions.
Small-Scale
Reconfigurability
Different programs have different resource needs
and even needs that vary dynamically over the course of the program's execution.
In addition to dynamic code manipulation, we are investigating dynamic
hardware
manipulation.
The goal is to dynamically adapt the hardware
to more directly serve
the program's needs. With proper design, a judicious amount of reconfigurable
hardware can provide substantial flexibility, and this Dynaptable organization
gives the necessary performance, functionality, and power characteristics
without resorting to FPGAs. This is joint work with
John
Lach, Mircea
Stan, and Zhijian Lu
from the U.Va. ECE department.
New
Multithreading Techniques
Multithreaded processors allow multiple threads of control or multiple
applications to coexist on the same processor. The goal is to improve
processor utilization and reduce inter-process communication and synchronization
delays without reducing per-thread performance. We are currently
exploring three multi-threaded organizations. Differential
multithreading (dMT) focuses on small, single-pipeline processors for
embedded environments, and interleaves the execution of multiple threads
in response to stalls, in order to obtain high utilization. Our results
suggest that dMT permits the use of smaller caches, substantially benefits
cacheless systems, and may even allow omission of the small branch predictors
that many current embedded processors use. Multipath
execution forks control upon encountering a difficult-to-predict conditional
branch, creating a thread to follow each path and hence eliminating the
possibility of a misprediction. Without high-accuracy techniques
for identifying these problematic branches, however, multipath demands
extremely high fetch bandwidth. And simultaneous
multithreading (SMT) allows multiple processes to each issue several
instructions during every cycle, thereby reducing not only wasted cycles,
but also reducing wasted issue slots within a cycle.
We are also engaged in research on real-time control and multithreading
to improve the performance of the control system for magnetic bearing control
in an energy-storage flywheel. This is joint work with Bin Huang,
Marty
Humphrey, Edgar Hilton, and Paul
Allaire.
Simulation
Evaluating approaches like those described above is typically done using
simulation.
For our research we use the SimpleScalar
toolkit from Wisconsin and some of
our own derivative simulators, especially HydraScalar
and Wattch.
HydraScalar extends the detail of the branch handling and reimplements
the pipeline and out-of-order execution to permit multipath execution.
Wattch adds a model of dynamic power dissipation on top of SimpleScalar's
sim-outorder
simulator. For thermal simulation, we will soon be publicly releasing
our thermal model, HotSpot, and we have just released our MRRL
tools for fast warmup.
Regardless of the simulator, performance
analysis is prone to numerous pitfalls. Some classic pitfalls
include modeling perfect structures, and an especially severe pitfall
is to assume perfect branch prediction. This exposes much more
instruction-level parallelism (ILP) than any realistic processor could.
As a result other optimizations like cache optimizations or greater degrees
of out-of-order execution may look far more profitable than they realistically
should. Another classic pitfall is to simulate only 50 million (M),
100 million, or even 1 billion instructions from the beginning of
a program's execution. This is done because cycle-level simulations
are slow, simulating only 100,000-500,000 instructions per second, while
many programs run for billions or hundreds of billions of instructions.
Unfortunately, many programs have very unrepresentative startup behavior
that can last even for 1-2 billion instructions–much longer than the 50-100
M instructions sometimes simulated. We
have shown that simulating only 50 M instructions does yield representative
results,
but only if taken from a representative part of the program's
execution. If the simulation window is instead taken from
the beginning of the program's execution, wildly inaccurate results can
occur. We have also shown that the state of large structures like
caches can be maintained across fast-forward periods without the need for
expensive warm up using a technique that we call MRRL.
This technique works with both single-sample and multiple-sample simulation
styles. We have just released a set of tools
for easily combining MRRL with your choice of sampling regime.
New Benchmarks
and the "Benchmark Challenge"
SPECcpu provides a number of programs
that can be used to characterize CPU performance, but we are always looking
for new programs and inputs that exhibit interesting, real-world behavior
not represented in the SPEC suite. We are also looking for "microbenchmarks"
that carefully isolate the behavior of one aspect of the processor or one
specific programming idiom.
Take
the Benchmark Challenge! We are
attempting to assemble a suite of CPU-intensive benchmarks and a suite
of microbenchmarks, both to augment the SPEC suite in computer architecture
and performance-evaluation research. If you have a good program or
microbenchmark, please send it to us! For maximum portability, the
program must be written in ANSI C and be POSIX-compliant, and the programs
must of course be publicly available. Please include source code,
documentation of the algorithm and documentation of how to compile and
run the program, an explanation of the novelty of the benchmark, and data
characterizing the benchmark's behavior. Any contributions that we
include in our suite will of course be credited to the contributor.
Our first contribution is a set of some small
neural-net and image modeling programs with various branch-prediction
and cache behavior that were developed by Sui Kwan Chan for her senior
thesis.
Programs that exhibit poor branch-predictor behavior
and programs that have a large branch footprint are of special interest.
Prior Computer
Architecture Research & Activities at U.Va.
A Framework
for the Analysis of Caching Systems
Weird Machine
Stream Memory Controller
Memory ACcess Evaluation (MACE)
Counterflow Pipeline
Processor
CPU
info collected in CS 854 on the Pentium III, Pentium 4, Athlon, Itanium,
and 21264
Current LAVA Lab Members
Graduate Students (including affiliated students):
 Michele
Co
Michele
Co
Wei
Huang,
U.Va. ECE
(advisor:
Mircea
Stan)
Philo
Juang, Princeton
EE (advisor: Margaret
Martonosi)
Yingmin
Li
Zhijian
Lu, U.Va. ECE
(advisor:
John
Lach)
Karthik
Sankaranarayanan
Sivakumar
Velusamy
Yan
Zhang, U.Va.
ECE
(advisor:
Mircea
Stan)
Undergraduate Students:
Arun
Thomas
Yuriy
Zilbergleyt
Visitors:
David
Tarjan, ETH-Zurich
Alumni:
Ph.D.
John
Haskins (2003)
Dee
A.B. Weikle (2001)
MS or MCS
Dharmesh
Parikh (2003)
Marco
Barcella (2002), U.Va.
ECE (advisor:
Mircea
Stan)
Kevin
Hirst (2002)
Michele
Co (2001)
BS
Jean
Ablutz (2001)
Edwin
Bauer (2002)
Sui
Kwan Chan (2001)
John
Erdman (2002)
Philo
Juang (2000)
Steve
Kelley (2001)
Paul
Lamanna (2002)
Adrian
Lanning (2000)
John
Miranda (2001)
Adam
Spanberger (2002)
Affiliates:
Tarek
Abdelzaher,
U.Va.
CS
Paul
Allaire,
U.Va.
MAE
David
I. August,
Princeton
CS
Douglas
W. Clark, Princeton
CS
Jack
Davidson,
U.Va.
CS
Phil
Diodato, Agere Corp.
Marty
Humphrey,
U.Va.
CS
Stefanos
Kaxiras, Agere Corp.
John
Lach,
U.Va.
ECE
Margaret
Martonosi, Princeton
EE
Sally
McKee, Cornell
ECE
Mircea
Stan,
U.Va.
ECE
William
A. Wulf,
U.Va.
CS and President, National Academy of
Engineering


 And we thank the National Science Foundation,
Intel,
and the University of Virginia Fund for Excellence in Science and Technology
for their generous support, including NSF ITR and CAREER awards. (Any
opinions, findings, and conclusions or recommendations expressed in this
material are those of the author(s) and do not necessarily reflect the
views of the funding entities.)
And we thank the National Science Foundation,
Intel,
and the University of Virginia Fund for Excellence in Science and Technology
for their generous support, including NSF ITR and CAREER awards. (Any
opinions, findings, and conclusions or recommendations expressed in this
material are those of the author(s) and do not necessarily reflect the
views of the funding entities.)
Selected Publications
-
K. Skadron, M. R. Stan, W. Huang, S. Velusamy, D. Tarjan, and K. Sankaranarayanan.
“Temperature-Aware Microarchitecture.” In Proceedings of the 30th
International Symposium on Computer Architecture, June 2003, to appear.
-
Y. Zhang, D. Parikh, K. Sankaranarayanan, K. Skadron, and M. Stan.
"HotLeakage: A Temperature-Aware Model of Subthreshold and Gate Leakage
for Architects." Tech Report CS-2003-05, Univ. of Virginia Dept.
of Computer Science, Mar. 2003. (postscript
| pdf | abstract
| software)
-
Z. Lu, J. Lach, M. Stan, and K. Skadron. “Alloyed Branch History:
Combining Global and Local Branch History for Robust Performance,” International
Journal of Parallel Programming, Kluwer, volume 31, number 2, Apr.
2003. (abstract)
-
J.W. Haskins, Jr. and K. Skadron. “Memory Reference Reuse Latency:
Accelerated Sampled Microarchitecture Simulation.” In Proceedings
of the 2003 IEEE International Symposium on Performance Analysis of Systems
and Software, pp. 195-203, Mar. 2003. (postscript
| pdf
| abstract | software)
-
N. Goodnight, G. Lewin, D. Luebke, and K. Skadron. “A Multigrid Solver
for Boundary-Value Problems Using Programmable Graphics Hardware.”
Tech Report CS-2003-03, Univ. of Virginia Dept. of Computer Science, Jan.
2003. (pdf | abstract)
-
Z. Lu, J. Hein, M. Humphrey, M. Stan, J. Lach, and K. Skadron. “Control-Theoretic
Dynamic Frequency and Voltage Scaling for Multimedia Workloads.”
In Proceedings of the 2002 International Conference on Compilers, Architectures,
and Synthesis for Embedded Systems, pp. 156-163, Oct. 2002. (postscript
| pdf | abstract)
-
P. Juang, P. Diodato, S. Kaxiras, K. Skadron, Z. Hu, M. Martonosi, and
D. W. Clark. “Implementing Decay Techniques using 4T Quasi-Static
Memory Cells,” Computer Architecture Letters (www.comp-arch-letters.org),
vol. 1, Sept. 2002. (postscript
| pdf
| abstract)
-
Z. Hu, P. Juang, K. Skadron, D. Clark, and M. Martonosi. “Applying
Decay Strategies to Branch Predictors for Leakage Energy Savings.”
To appear in Proceedings of the 2002 International Conference on Computer
Design, pp. 442-45, Sept. 2002. (pdf
| abstract)
-
S. Velusamy, K. Sankaranarayanan, D. Parikh, T. Abdelzaher, and K. Skadron.
"Adaptive Cache Decay using Formal Feedback Control." To appear in
the Workshop on Memory Performance Issues in conjunction with ISCA-29,
May 2002. (postscript | pdf
| abstract) [note: includes
re-evaluation of Zhou, Toburen, Rotenberg, and Conte's "adaptive
mode control" (AMC) technique.]
-
K. Skadron, T. Abdelzaher, and M. Stan. "Control-Theoretic Techniques
and Thermal-RC Modeling for Accurate and Localized Dynamic Thermal Management."
In Proceedings of the Eighth International Symposium on High-Performance
Computer Architecture, Feb. 2002, pgs. 17-28. (postscript
| pdf | abstract
| erratum)
-
D. Parikh, K. Skadron, Y. Zhang, M. Barcella, and M. Stan. "Power
Issues Related to Branch Prediction." In Proceedings of the Eighth
International Symposium on High-Performance Computer Architecture,
Feb. 2002, pgs. 233-44. (postscript
| pdf
| abstract)
Complete list
of publications
Software Releases
HotSpot software
HotLeakage
beta
MRRL
tools for fast but provably accurate warm-up
HydraScalar
1.0, now available by request
HotSpot
-- a thermal model, to be released later this year
LAVA Facilities
58
dual-CPU Pentium-III/4 class machines
1
Alpha 21264/466 MHz/Tru64-Unix DS-10 server
9
SunBlade-100 workstations
SimpleScalar
4.0 beta, targets multiple instruction sets
Wattch
1.02, targets PISA or Alpha AXP
Compaq
Alpha-AXP C, C++, and Fortran compilers

( Top of Page | Research
| People | Publications | Facilities
)
Department of Computer Science
School of Engineering and Applied
Science
University of Virginia, Charlottesville,
Virginia 22904
(434) 982-2200, FAX: (434) 982-2214
Email web page comments to webman@cs.virginia.edu
Email CS admission inquiries to inquiry@cs.virginia.edu
© Kevin Skadron, 2001, 2002, 2003
